|
|
|
|
@ -0,0 +1,503 @@
|
|
|
|
|
Долгожданный туториал по управлению сторонними WEB приложениями с помощью pyOpenRPA. Во 2-й части мы разберем принципы роботизированного воздействия на HTML/JS. А также своими руками сделаем небольшого, но очень показательного робота.
|
|
|
|
|
|
|
|
|
|
Этот робот будет полезен тем, для кого актуальна тема покупки/продажи недвижимости.
|
|
|
|
|
|
|
|
|
|

|
|
|
|
|
|
|
|
|
|
# Для тех, кто с нами впервые
|
|
|
|
|
[pyOpenRPA](https://gitlab.com/UnicodeLabs/OpenRPA) - это open source [RPA платформа](https://ru.wikipedia.org/wiki/Robotic_process_automation), которая **в полной мере позволяет заменить топовые коммерческие RPA платформы**.
|
|
|
|
|
|
|
|
|
|
Подробнее про то, чем же она полезна, можно [почитать здесь](https://habr.com/ru/post/506766/).
|
|
|
|
|
|
|
|
|
|
# Навигация по туториалам pyOpenRPA
|
|
|
|
|
Туториал сверстан в виде серии статей, в которых будут освещаться ключевые технологии, необходимые для RPA.
|
|
|
|
|
|
|
|
|
|
Освоив эти технологии, у вас появится возможность углубиться в специфику той задачи, которая поставлена перед вами.
|
|
|
|
|
|
|
|
|
|
**Перечень статей-туториалов (опубликованные и планируемые):**
|
|
|
|
|
- [Отказываемся от платных RPA платформ и базируемся на OpenSource (pyOpenRPA)](https://habr.com/ru/post/506766/)
|
|
|
|
|
- [pyOpenRPA туториал. Управление оконными GUI приложениями](https://habr.com/ru/post/509644/)
|
|
|
|
|
- \>> [pyOpenRPA туториал. Управление WEB приложениями (то, что мы смотрим в Chrome, Firefox, Opera)](https://habr.com/ru/post/515310/)
|
|
|
|
|
- pyOpenRPA туториал. Управление клавиатурой & мышью
|
|
|
|
|
- pyOpenRPA туториал. Распознавание графических объектов на экране
|
|
|
|
|
|
|
|
|
|
А теперь перейдем к самому туториалу.
|
|
|
|
|
|
|
|
|
|
<cut/>
|
|
|
|
|
|
|
|
|
|
# Немного теории и терминов
|
|
|
|
|
|
|
|
|
|
[Из википедии]
|
|
|
|
|
|
|
|
|
|
Веб-приложение — клиент-серверное приложение, в котором клиент взаимодействует с веб-сервером при помощи браузера. Логика веб-приложения распределена между сервером и клиентом, хранение данных осуществляется, преимущественно, на сервере, обмен информацией происходит по сети. Одним из преимуществ такого подхода является тот факт, что клиенты не зависят от конкретной операционной системы пользователя, поэтому веб-приложения являются межплатформенными службами.
|
|
|
|
|
|
|
|
|
|
Веб приложения стали широко использоваться в конце 1990-х — начале 2000-х годов.
|
|
|
|
|
|
|
|
|
|
[Ссылка на источник](https://ru.wikipedia.org/wiki/%D0%92%D0%B5%D0%B1-%D0%BF%D1%80%D0%B8%D0%BB%D0%BE%D0%B6%D0%B5%D0%BD%D0%B8%D0%B5)
|
|
|
|
|
|
|
|
|
|
Ок, с выдержкой из вики все #КрутоУмно, но от этого не легче (для тех, кто в этой теме дилетант). Продемонстрирую устройство WEB приложения на примере "Что видим мы?"/"Что видит робот?". Для этого отправимся на сайт одной известной WEB площадки по объявлениям по недвижимости
|
|
|
|
|
|
|
|
|
|
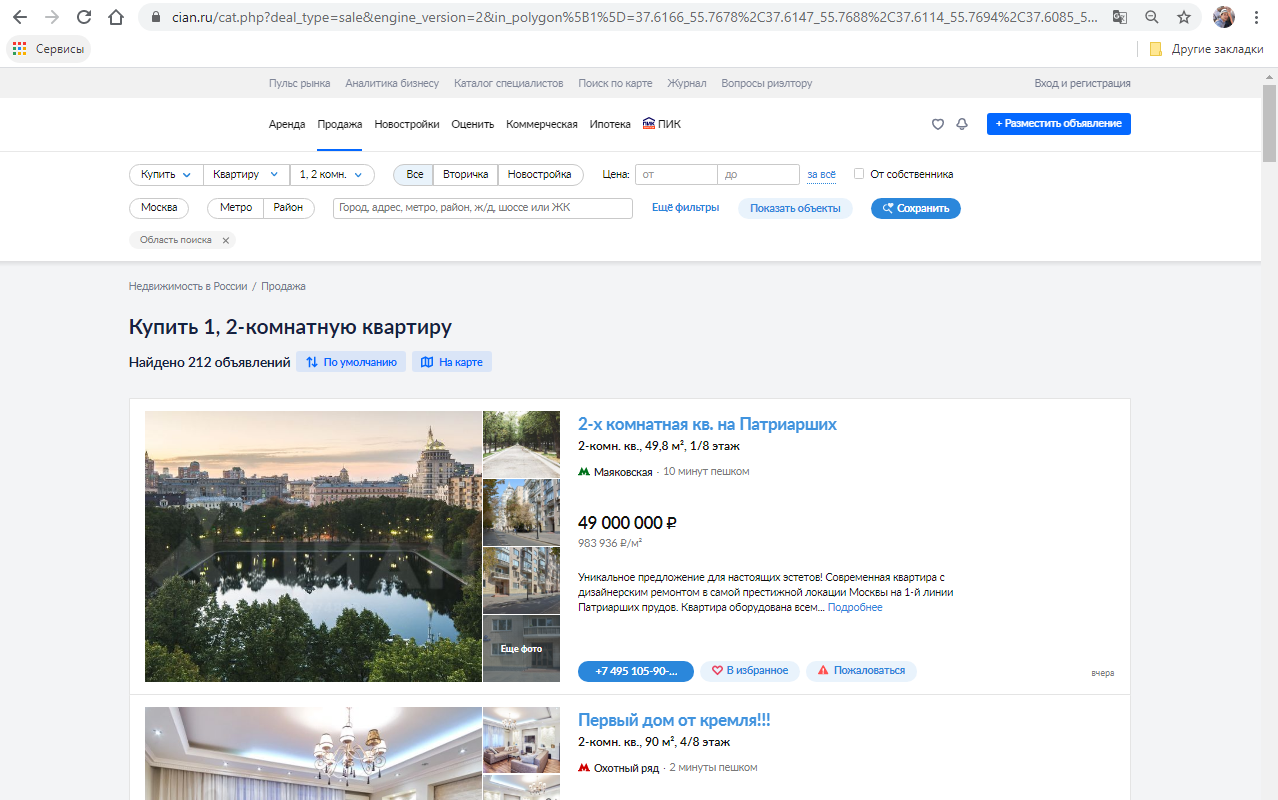
## Что видим мы?
|
|
|
|
|
Мы видим красиво сверстанный сайт с интуитивно понятным интерфейсом, на котором можно найти интересные объявления о продаже/сдаче в аренду недвижимости.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
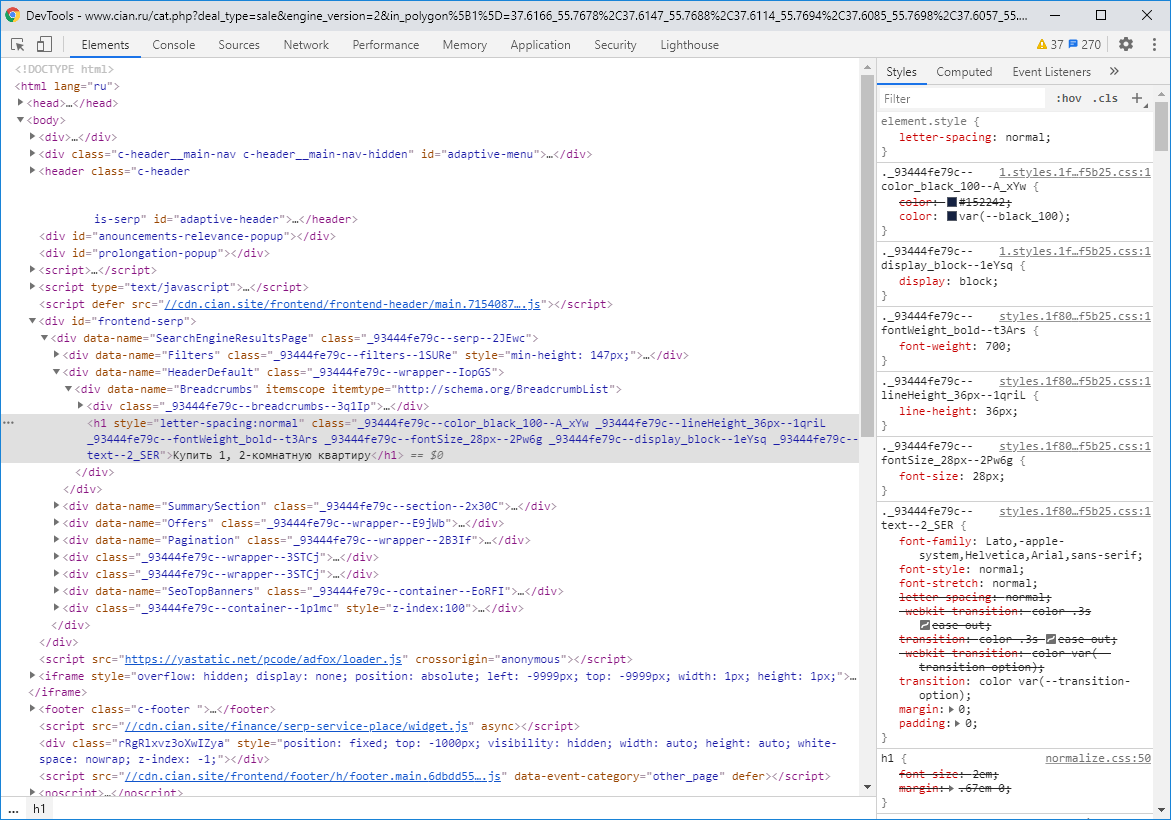
## Что видит робот?
|
|
|
|
|
Робот видит огромную гипертекстовую разметку [HTML](https://ru.wikipedia.org/wiki/HTML) с примесью алгоритмического кода [JS](https://ru.wikipedia.org/wiki/JavaScript) и завернутого в каскадную таблицу стилей [CSS](https://ru.wikipedia.org/wiki/CSS). Увлекательно, правда? :)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
## Интерпретация
|
|
|
|
|
WEB приложения - это **один из самых легко роботизируемых классов приложений**. Обилие инструментов + технологий позволяют реализовывать практически любую поставленную задачу в кооперации с ними.
|
|
|
|
|
|
|
|
|
|
Управлять WEB страницей можно с помощью разных технологий адресации: CSS, XPath, id, class, attribute. Мы будем взаимодействовать со страницей с помощью CSS селекторов.
|
|
|
|
|
|
|
|
|
|
<cut/>
|
|
|
|
|
|
|
|
|
|
# (По шагам) робот своими руками
|
|
|
|
|
В этом туториале мы будем заниматься разработкой робота, который оперирует на одном из самых популярных порталов по объявлениям по недвижимости в РФ (тема одна из актуальных для многих).
|
|
|
|
|
|
|
|
|
|
В качестве примера поставим себе следующую задачу: **Разработать робота, который будет извлекать список всех объявлений по ранее преднастроенному фильтру**. Все извлеченные объявления сохранить как датасет в файл .json со следующей структурой:
|
|
|
|
|
```
|
|
|
|
|
{
|
|
|
|
|
"SearchKeyStr": "МСК_Тверской", # Ключевое слово поиска
|
|
|
|
|
"SearchTitleStr": "Москва, район Тверской", # Заголовок поиска
|
|
|
|
|
"SearchURLStr": "https://www.cian.ru/cat.php?deal_type=sale&engine_version=2&in_polygon%5B1%5D=37.6166_55.7678%2C37.6147_55.7688%2C37.6114_55.7694%2C37.6085_55.7698%2C37.6057_55.77%2C37.6018_55.77%2C37.5987_55.77%2C37.5961_55.7688%2C37.5942_55.7677%2C37.5928_55.7663%2C37.5915_55.7647%2C37.5908_55.7631%2C37.5907_55.7616%2C37.5909_55.7595%2C37.5922_55.7577%2C37.5944_55.7563%2C37.5968_55.7555%2C37.6003_55.7547%2C37.603_55.7543%2C37.6055_55.7542%2C37.6087_55.7541%2C37.6113_55.7548%2C37.6135_55.756%2C37.6151_55.7574%2C37.6163_55.7589%2C37.6179_55.7606%2C37.6187_55.7621%2C37.619_55.7637%2C37.6194_55.7651%2C37.6193_55.7667%2C37.6178_55.7679%2C37.6153_55.7683%2C37.6166_55.7678&offer_type=flat&polygon_name%5B1%5D=%D0%9E%D0%B1%D0%BB%D0%B0%D1%81%D1%82%D1%8C+%D0%BF%D0%BE%D0%B8%D1%81%D0%BA%D0%B0&room1=1&room2=1", # URL of the CIAN search [str]
|
|
|
|
|
"SearchDatetimeStr": "2020-08-01 09:33:00.838081", # Дата, на которую была сформирована выгрузка
|
|
|
|
|
"SearchItems": { # Перечень извлеченных ценовых объявлений
|
|
|
|
|
"https://www.cian.ru/sale/flat/219924574/:": { # URL ссылка на ценовое объявление
|
|
|
|
|
"TitleStr": "3-комн. кв., 31,4 м², 5/8 этаж", # Заголовок ценового объявления
|
|
|
|
|
"PriceFloat": 10000000.0, # Стоимость общая
|
|
|
|
|
"PriceSqmFloat": 133333.0, # Стоимость на 1 кв. м.
|
|
|
|
|
"SqMFloat": 31.4, # Кол-во кв. м.
|
|
|
|
|
"FloorCurrentInt": 5, # Этаж лота по объявлению
|
|
|
|
|
"FloorTotalInt": 8, # Этажей в доме всего
|
|
|
|
|
"RoomCountInt": 3 # Кол-во комнат
|
|
|
|
|
}
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
}
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
<cut/>
|
|
|
|
|
|
|
|
|
|
## Шаг 0. Подготовим проект для нового робота (развернем pyOpenRPA)
|
|
|
|
|
В отличии от подавляющего большинства RPA платформ, в pyOpenRPA реализован принципиально иной подход по подключению к проекту, а именно: если в них структуру проекта определяет сама RPA платформа, то в pyOpenRPA структуру проекта определяете Вы и только Вы. Это дает больше гибкости и возможности по использованию этой RPA технологии в других направлениях (использовать pyOpenRPA как обычную библиотеку Python).
|
|
|
|
|
|
|
|
|
|
**Доступно несколько вариантов загрузки [pyOpenRPA](https://gitlab.com/UnicodeLabs/OpenRPA):**
|
|
|
|
|
- Вариант 1, простой. Скачать преднастроенную портативную версию с [GitLab страницы проекта](https://gitlab.com/UnicodeLabs/OpenRPA)
|
|
|
|
|
- Вариант 2, сложный. Установить pyOpenRPA в свою версию интерпретатора Python 3 (pip install pyOpenRPA)
|
|
|
|
|
|
|
|
|
|
Я рекомендую воспользоваться простым вариантом (вариант 1). Преднастроенная версия не требуется каких-либо настроек инфраструктуры. Здесь в лучших традициях pyOpenRPA реализован принцип, когда пользователь скачивает репозиторий, и у него уже все настроено из коробки - пользователю остается лишь писать скрипт робота. #Enjoy :)
|
|
|
|
|
<cut/>
|
|
|
|
|
|
|
|
|
|
## Шаг 1. Создать проект робота
|
|
|
|
|
Для того, чтобы начать проект робота, необходимо создать папку проекта. В дальнейшем я затрону тему организации папок проектов для промышленных программных роботов. Но на текущий момент не буду заострять внимание на этом, чтобы сконцентрироваться непосредственно на основном - на логике работы с WEB страницами.
|
|
|
|
|
|
|
|
|
|
**Ниже приведу зависимости проекта от сторонних компонентов:**
|
|
|
|
|
- Selenium WebDriver
|
|
|
|
|
- Google Chrome или Mozilla Firefox или Internet Explorer
|
|
|
|
|
- Python 3
|
|
|
|
|
|
|
|
|
|
Если вы пошли по варианту 1 (см. шаг 0), то у Вас все эти компоненты уже будут развернуты и настроены внутри скачанного репозитория pyOpenRPA (#Удобно). Репозиторий pyOpenRPA уже содержит все необходимые portable версии требуемых программ (Google Chrome, Mozilla Firefox, Python3 32|64 и т.д.).
|
|
|
|
|
|
|
|
|
|
Вы наверняка заметили, что в pyOpenRPA используется [Selenium](https://habr.com/ru/post/152653/). Этот компонент является одним из лучших отказоустойчивых компонентов по внедрению в WEB. Именно поэтому мы его и будем использовать в pyOpenRPA.
|
|
|
|
|
|
|
|
|
|
**Создадим следующую структуру проекта:**
|
|
|
|
|
- Репозиторий pyOpenRPA > Wiki > RUS_Tutorial > WebGUI_Habr:
|
|
|
|
|
- Файл "3. MonitoringCIAN_Run_64.py" - скрипт робота, который мониторит WEB площадку
|
|
|
|
|
- Файл "3. MonitoringCIAN_Run_64.cmd" - скрипт запуска робота с 1-го клика по аналогии с .exe файлами
|
|
|
|
|
|
|
|
|
|
**Ниже приведу пример "3. MonitoringCIAN_Run_64.cmd" файла:**
|
|
|
|
|
```
|
|
|
|
|
cd %~dp0..\..\..\Sources
|
|
|
|
|
..\Resources\WPy64-3720\python-3.7.2.amd64\python.exe "..\Wiki\RUS_Tutorial\WebGUI_Habr\3. MonitoringCIAN_Run_64.py"
|
|
|
|
|
pause >nul
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
**Для инициализации Selenium WebDriver воспользуемся следующей функцией:**
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
##########################
|
|
|
|
|
# Init the Chrome web driver
|
|
|
|
|
###########################
|
|
|
|
|
def WebDriverInit(inWebDriverFullPath, inChromeExeFullPath, inExtensionFullPathList):
|
|
|
|
|
# Set full path to exe of the chrome
|
|
|
|
|
lWebDriverChromeOptionsInstance = webdriver.ChromeOptions()
|
|
|
|
|
lWebDriverChromeOptionsInstance.binary_location = inChromeExeFullPath
|
|
|
|
|
# Add extensions
|
|
|
|
|
for lExtensionItemFullPath in inExtensionFullPathList:
|
|
|
|
|
lWebDriverChromeOptionsInstance.add_extension (lExtensionItemFullPath)
|
|
|
|
|
# Run chrome instance
|
|
|
|
|
lWebDriverInstance = None
|
|
|
|
|
if inWebDriverFullPath:
|
|
|
|
|
# Run with specified web driver path
|
|
|
|
|
lWebDriverInstance = webdriver.Chrome(executable_path = inWebDriverFullPath, options=lWebDriverChromeOptionsInstance)
|
|
|
|
|
else:
|
|
|
|
|
lWebDriverInstance = webdriver.Chrome(options = lWebDriverChromeOptionsInstance)
|
|
|
|
|
# Return the result
|
|
|
|
|
return lWebDriverInstance
|
|
|
|
|
```
|
|
|
|
|
<cut/>
|
|
|
|
|
|
|
|
|
|
## Шаг 2. Запустить WEB инструменты разработчика и сформировать CSS селекторы
|
|
|
|
|
В нашем случае WEB инструменты разработчика мы будем использовать из Google Chrome, который предустановлен в репозитории pyOpenRPA (вариант 1 из шага 0).
|
|
|
|
|
|
|
|
|
|
**Откроем Google Chrome и инструменты разработчика** (pyOpenRPA repo\\Resources\GoogleChromePortable\App\Chrome-bin\chrome.exe, после чего Ctrl + Shift + i)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
**Откроем в браузере сайт, который мы будем анализировать. Сформируем область поиска и отобразить обнаруженные ценовые предложения в виде списка.**
|
|
|
|
|
|
|
|
|
|
[Пример поискового запроса](https://www.cian.ru/cat.php?deal_type=sale&engine_version=2&in_polygon%5B1%5D=37.6166_55.7678%2C37.6147_55.7688%2C37.6114_55.7694%2C37.6085_55.7698%2C37.6057_55.77%2C37.6018_55.77%2C37.5987_55.77%2C37.5961_55.7688%2C37.5942_55.7677%2C37.5928_55.7663%2C37.5915_55.7647%2C37.5908_55.7631%2C37.5907_55.7616%2C37.5909_55.7595%2C37.5922_55.7577%2C37.5944_55.7563%2C37.5968_55.7555%2C37.6003_55.7547%2C37.603_55.7543%2C37.6055_55.7542%2C37.6087_55.7541%2C37.6113_55.7548%2C37.6135_55.756%2C37.6151_55.7574%2C37.6163_55.7589%2C37.6179_55.7606%2C37.6187_55.7621%2C37.619_55.7637%2C37.6194_55.7651%2C37.6193_55.7667%2C37.6178_55.7679%2C37.6153_55.7683%2C37.6166_55.7678&offer_type=flat&polygon_name%5B1%5D=%D0%9E%D0%B1%D0%BB%D0%B0%D1%81%D1%82%D1%8C+%D0%BF%D0%BE%D0%B8%D1%81%D0%BA%D0%B0&room1=1&room2=1)
|
|
|
|
|
|
|
|
|
|

|
|
|
|
|
|
|
|
|
|
Для того, чтобы подобрать CSS селектор нам помогут инструменты разработчика Google Chrome. Подробнее узнать про устройство CSS селекторов можно [здесь по ссылке](https://learn.javascript.ru/css-selectors)
|
|
|
|
|
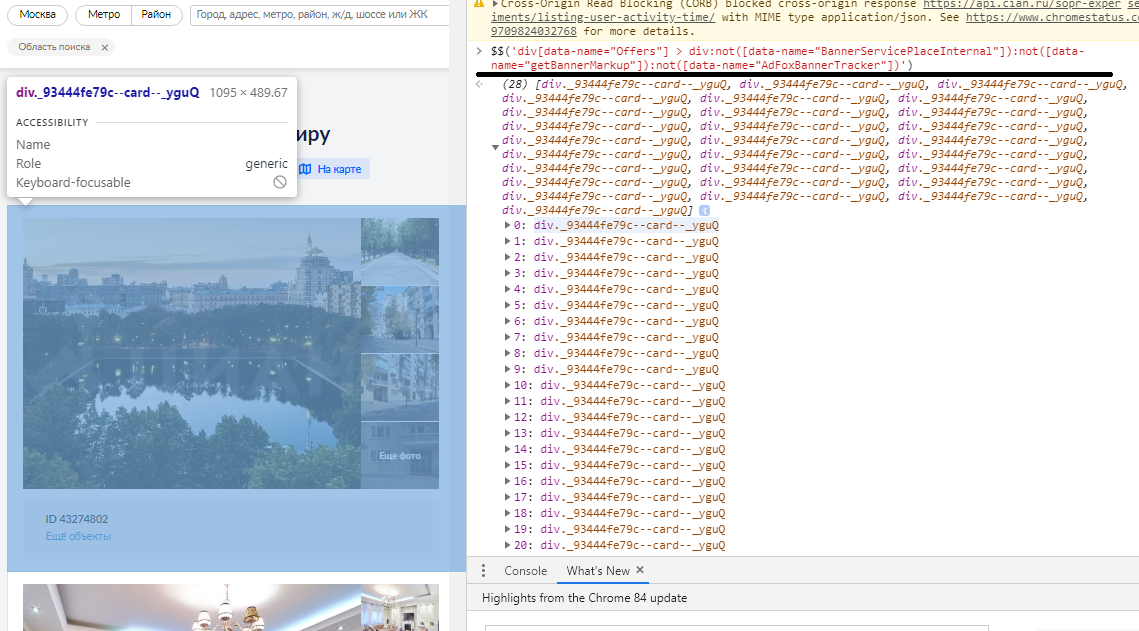
Для проверки правильности CSS селектора я буду делать следующую проверку в инструментах разработчика на вкладке "Console". На картинке представлен пример того, как проводится проверки правильности CSS селектора для извлечения списка ценовых предложений.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
**Подберем CSS селектор для выборки списка ценовых предложений на странице.**
|
|
|
|
|
|
|
|
|
|
При составлении селектора выяснилось, что в список объявлений встроены рекламные баннеры, которые не содержат информацию о ценовом предложении.
|
|
|
|
|
|
|
|
|
|
И таких видов рекламных баннеров было обнаружено несколько видов:
|
|
|
|
|
- div[data-name="BannerServicePlaceInternal"]
|
|
|
|
|
- div[data-name="getBannerMarkup"]
|
|
|
|
|
- div[data-name="AdFoxBannerTracker"]
|
|
|
|
|
|
|
|
|
|
В связи с этим CSS селектор должен быть скорректирован таким образом, чтобы исключить из выборки такие виды баннеров. Ниже приведен готовый CSS селектор.
|
|
|
|
|
|
|
|
|
|
- CSS селектор, Список ценовых предложений: div[data-name="Offers"] > div:not([data-name="BannerServicePlaceInternal"]):not([data-name="getBannerMarkup"]):not([data-name="AdFoxBannerTracker"])
|
|
|
|
|
|
|
|
|
|
**Подберем CSS селекторы по извлечению параметров ценового предложения: Заголовок, Стоимость общая, URL ссылка на карточку.**
|
|
|
|
|
|
|
|
|
|
- CSS селектор, Заголовок: div[data-name="TopTitle"],div[data-name="Title"]
|
|
|
|
|
- CSS селектор, Стоимость общая: div[data-name="Price"] > div[class*="header"],div[data-name="TopPrice"] > div[class*="header"]
|
|
|
|
|
- CSS селектор, URL ссылка на карточку: a[class*="--header--"]
|
|
|
|
|
|
|
|
|
|
**Подберем CSS селектор для извлечения кнопки на следующую страницу.**
|
|
|
|
|
|
|
|
|
|
- CSS селектор, Указатель на следующую страницу: div[data-name="Pagination"] li[class*="active"] + li a
|
|
|
|
|
|
|
|
|
|
<cut/>
|
|
|
|
|
|
|
|
|
|
## Шаг 3. Обработать/преобразовать получаемые данные
|
|
|
|
|
На предыдущем шаге мы успешно подобрали все необходимые CSS селекторы. Теперь нам нужно грамотно извлечь информацию, а потом и обработать ее.
|
|
|
|
|
|
|
|
|
|
В результате обработки ценового предложения у нас будет сформирована структура следующего вида:
|
|
|
|
|
```
|
|
|
|
|
lOfferItemInfo = { # Item URL with https
|
|
|
|
|
"TitleStr": "3-комн. кв., 31,4 м², 5/8 этаж", # Offer title [str]
|
|
|
|
|
"PriceFloat": 10000000.0, # Price [float]
|
|
|
|
|
"PriceSqmFloat": 133333.0, # CALCULATED Price per square meters [float]
|
|
|
|
|
"SqMFloat": 31.4, # Square meters in flat [float]
|
|
|
|
|
"FloorCurrentInt": 5, # Current floor [int]
|
|
|
|
|
"FloorTotalInt": 8, # Current floor [int]
|
|
|
|
|
"RoomCountInt": 3 # Room couint [int]
|
|
|
|
|
}
|
|
|
|
|
```
|
|
|
|
|
**Для начала получим список элементов ценовых предложений.**
|
|
|
|
|
```
|
|
|
|
|
lOfferListCSSStr = 'div[data-name="Offers"] > div:not([data-name="BannerServicePlaceInternal"]):not([data-name="getBannerMarkup"]):not([data-name="AdFoxBannerTracker"])'
|
|
|
|
|
lOfferList = inWebDriver.find_elements_by_css_selector(css_selector=lOfferListCSSStr)
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
**Далее циклическая обработка каждого ценового предложения.**
|
|
|
|
|
```
|
|
|
|
|
for lOfferItem in lOfferList:
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
**Извлечем параметры из WEB страницы: Заголовок, Стоимость общая, URL на карточку.**
|
|
|
|
|
```
|
|
|
|
|
lTitleStr = lOfferItem.find_element_by_css_selector(css_selector='div[data-name="TopTitle"],div[data-name="Title"]').text # Extract title text
|
|
|
|
|
lPriceStr = lOfferItem.find_element_by_css_selector(css_selector='div[data-name="Price"] > div[class*="header"],div[data-name="TopPrice"] > div[class*="header"]').text # Extract total price
|
|
|
|
|
lURLStr = lOfferItem.find_element_by_css_selector(css_selector='a[class*="--header--"]').get_attribute("href") # Extract offer URL
|
|
|
|
|
lOfferItemInfo["TitleStr"] = lTitleStr # set the title
|
|
|
|
|
lPriceStr = lPriceStr.replace(" ","").replace("₽","") # Remove some extra symbols
|
|
|
|
|
lOfferItemInfo["PriceFloat"] = round(float(lPriceStr),2) # Convert price to the float type
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
**Извлечем недостающие параметры алгоритмическим путем.**
|
|
|
|
|
- Если в заголовке **содержится** слово "Апартаменты"
|
|
|
|
|
```
|
|
|
|
|
lREResult = re.search(r".*, (\d*,?\d*) м², (\d*)/(\d*) эта.", lTitleStr) # run the re
|
|
|
|
|
lOfferItemInfo["RoomCountInt"] = 1 # Room count
|
|
|
|
|
lSqmStr = lREResult.group(1)
|
|
|
|
|
lSqmStr= lSqmStr.replace(",",".")
|
|
|
|
|
lOfferItemInfo["SqMFloat"] = round(float(lSqmStr),2) # sqm count
|
|
|
|
|
lOfferItemInfo["FloorCurrentInt"] = int(lREResult.group(2)) # Floor current
|
|
|
|
|
lOfferItemInfo["FloorTotalInt"] = int(lREResult.group(3)) # Floor total
|
|
|
|
|
lOfferItemInfo["PriceSqmFloat"] = round(lOfferItemInfo["PriceFloat"] / lOfferItemInfo["SqMFloat"],2) # Sqm per M
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
- Если в заголовке **не содержится** слово "Апартаменты"
|
|
|
|
|
```
|
|
|
|
|
lREResult = re.search(r".*(\d)-комн. .*, (\d*,?\d*) м², (\d*)/(\d*) эта.", lTitleStr) # run the re
|
|
|
|
|
lOfferItemInfo["RoomCountInt"] = int(lREResult.group(1)) # Room count
|
|
|
|
|
lSqmStr = lREResult.group(2)
|
|
|
|
|
lSqmStr= lSqmStr.replace(",",".")
|
|
|
|
|
lOfferItemInfo["SqMFloat"] = round(float(lSqmStr),2) # sqm count
|
|
|
|
|
lOfferItemInfo["FloorCurrentInt"] = int(lREResult.group(3)) # Floor current
|
|
|
|
|
lOfferItemInfo["FloorTotalInt"] = int(lREResult.group(4)) # Floor total
|
|
|
|
|
lOfferItemInfo["PriceSqmFloat"] = round(lOfferItemInfo["PriceFloat"] / lOfferItemInfo["SqMFloat"],2) # Sqm per M
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
В примере выше применяется магия [регулярных выражений](https://ru.wikipedia.org/wiki/%D0%A0%D0%B5%D0%B3%D1%83%D0%BB%D1%8F%D1%80%D0%BD%D1%8B%D0%B5_%D0%B2%D1%8B%D1%80%D0%B0%D0%B6%D0%B5%D0%BD%D0%B8%D1%8F)
|
|
|
|
|
|
|
|
|
|
Для подбора правильных регулярных выражений я пользуюсь [online валидаторами типа таких](https://www.google.com/search?q=online+regex&oq=online+reg&aqs=chrome.0.0l2j69i57j0l5.5699j0j7&sourceid=chrome&ie=UTF-8)
|
|
|
|
|
|
|
|
|
|
**По окончанию обработки ценовых предложений выполним проверку на наличие указателя на следующую страницу, и (если такой указатель имеется) выполним переход на нее.**
|
|
|
|
|
|
|
|
|
|
Выше (на шаге 2) мы уже находили CSS селектор указателя на следующую страницу. Нам нужно выполнить действие клика .click() по этому элементу.
|
|
|
|
|
Но при тестировании выяснилось, что функция .click от Selenium отрабатывает некорректно для этой страницы (не происходит переключение). В связи с этим у нас есть уникальная возможность использовать функциональность JavaScript на самой странице через Selenium. А уже из JavaScript выяснилось, что функция нажатия по указателю страницы отрабатывает корректно. Для этого выполним следующую команду:
|
|
|
|
|
```
|
|
|
|
|
inWebDriver.execute_script("""document.querySelector('div[data-name="Pagination"] li[class*="active"] + li a').click()""")
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
После того как был отправлен сигнал на переключение страницы, необходимо дождаться ее загрузки. Только после появления новой страницы мы сможем перейти к обработке новых ценовых предложений.
|
|
|
|
|
```
|
|
|
|
|
# wait while preloader is active
|
|
|
|
|
lDoWaitBool = True
|
|
|
|
|
while lDoWaitBool:
|
|
|
|
|
lPreloaderCSS = inWebDriver.find_elements_by_css_selector(css_selector='div[class*="--preloadOverlay--"]') # So hard to catch the element :)
|
|
|
|
|
if len(lPreloaderCSS)>0: time.sleep(0.5) # preloader is here - wait
|
|
|
|
|
else: lDoWaitBool = False # Stop wait if preloader is dissappear
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
**Итоговую структуру сохраним в .json файл.**
|
|
|
|
|
```
|
|
|
|
|
# Check dir - create if not exists
|
|
|
|
|
if not os.path.exists(os.path.join('Datasets',lResult['SearchKeyStr'])):
|
|
|
|
|
os.makedirs(os.path.join('Datasets',lResult['SearchKeyStr']))
|
|
|
|
|
# Save result in file
|
|
|
|
|
lFile = open(f"{os.path.join('Datasets',lResult['SearchKeyStr'],lDatetimeNowStr.replace(' ','_').replace('-','_').replace(':','_').replace('.','_'))}.json","w",encoding="utf-8")
|
|
|
|
|
lFile.write(json.dumps(lResult))
|
|
|
|
|
lFile.close()
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
## Шаг 4. Обработка нештатных ситуаций
|
|
|
|
|
Этап тестирования - это один из самых важных этапов, который позволяет конвертировать вложенные усилия в реальный эффект. При тестировании кода на этом WEB приложении выяснилось, что могут происходить некоторые сбои. Ниже привожу те виды сбоев, которые встретились у меня:
|
|
|
|
|
- Зависает ползунок загрузки при переключении на сл. страницу
|
|
|
|
|
- При переключении на следующую страницу открывается совсем не следующая страница (иногда, но случалось :) )
|
|
|
|
|
|
|
|
|
|
Но роботы не боятся таких проблем (на то они и роботы :) ).
|
|
|
|
|
|
|
|
|
|
**Для каждого вида сбоя мы предусмотрим сценарий восстановления, который позволит роботы доделать свою работу до конца.**
|
|
|
|
|
- Зависает ползунок загрузки при переключении на сл. страницу
|
|
|
|
|
```
|
|
|
|
|
# wait while preloader is active. If timeout - retry all job
|
|
|
|
|
lTimeFromFLoat = time.time() # get current time in float (seconds)
|
|
|
|
|
lDoWaitBool = True
|
|
|
|
|
while lDoWaitBool:
|
|
|
|
|
lPreloaderCSS = inWebDriver.find_elements_by_css_selector(css_selector='div[class*="--preloadOverlay--"]')
|
|
|
|
|
if len(lPreloaderCSS)>0: time.sleep(0.5) # preloader is here - wait
|
|
|
|
|
else: lDoWaitBool = False # Stop wait if preloader is dissappear
|
|
|
|
|
if (time.time() - lTimeFromFLoat) > 15: # check if timeout is more than 15 seconds
|
|
|
|
|
lRetryJobBool = True # Loading error on page - do break, then retry the job
|
|
|
|
|
if inLogger: inLogger.warning(f"Ожидание загрузки страницы более {15} с., Робот повторит задание сначала")
|
|
|
|
|
break # break the loop
|
|
|
|
|
if lRetryJobBool == True: # break the loop if RetryJobBool is true
|
|
|
|
|
break
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
- При переключении на следующую страницу открывается совсем не следующая страница (иногда, но случалось :) )
|
|
|
|
|
```
|
|
|
|
|
lPageNumberInt = int(inWebDriver.find_element_by_css_selector(css_selector='li[class*="--active--"] span').text) # Get the current page int from web and check with iterator (if not equal - retry all job)
|
|
|
|
|
if lPageNumberInt == lPageCounterInt:
|
|
|
|
|
... Код робота ...
|
|
|
|
|
else:
|
|
|
|
|
lRetryJobBool = True
|
|
|
|
|
if inLogger: inLogger.warning(
|
|
|
|
|
f"Следующая страница по списку не была загружена. Была загружена страница: {lPageNumberInt}, Ожидалась страница: {lPageCounterInt}")
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
## Шаг 5. Консолидировать код в проекте робота
|
|
|
|
|
**Соберем все блоки воедино.**
|
|
|
|
|
|
|
|
|
|
Получим следующий пакет ([открыть на GitLab](https://gitlab.com/UnicodeLabs/OpenRPA/-/blob/master/Wiki/RUS_Tutorial/WebGUI_Habr/3.%20MonitoringCIAN_Run_64.py)):
|
|
|
|
|
```
|
|
|
|
|
# Init Chrome web driver with extensions (if applicable)
|
|
|
|
|
# Import section
|
|
|
|
|
from selenium import webdriver
|
|
|
|
|
import time
|
|
|
|
|
import re # Regexp to extract info from string
|
|
|
|
|
import json
|
|
|
|
|
import datetime
|
|
|
|
|
import os
|
|
|
|
|
import re
|
|
|
|
|
import copy
|
|
|
|
|
import logging
|
|
|
|
|
# Store structure (.json)
|
|
|
|
|
"""
|
|
|
|
|
{
|
|
|
|
|
"SearchKeyStr": "МСК_Тверской",
|
|
|
|
|
"SearchTitleStr": "Москва, район Тверской", # Title of the search [str]
|
|
|
|
|
"SearchURLStr": "https://www.cian.ru/cat.php?deal_type=sale&engine_version=2&in_polygon%5B1%5D=37.6166_55.7678%2C37.6147_55.7688%2C37.6114_55.7694%2C37.6085_55.7698%2C37.6057_55.77%2C37.6018_55.77%2C37.5987_55.77%2C37.5961_55.7688%2C37.5942_55.7677%2C37.5928_55.7663%2C37.5915_55.7647%2C37.5908_55.7631%2C37.5907_55.7616%2C37.5909_55.7595%2C37.5922_55.7577%2C37.5944_55.7563%2C37.5968_55.7555%2C37.6003_55.7547%2C37.603_55.7543%2C37.6055_55.7542%2C37.6087_55.7541%2C37.6113_55.7548%2C37.6135_55.756%2C37.6151_55.7574%2C37.6163_55.7589%2C37.6179_55.7606%2C37.6187_55.7621%2C37.619_55.7637%2C37.6194_55.7651%2C37.6193_55.7667%2C37.6178_55.7679%2C37.6153_55.7683%2C37.6166_55.7678&offer_type=flat&polygon_name%5B1%5D=%D0%9E%D0%B1%D0%BB%D0%B0%D1%81%D1%82%D1%8C+%D0%BF%D0%BE%D0%B8%D1%81%D0%BA%D0%B0&room1=1&room2=1", # URL of the CIAN search [str]
|
|
|
|
|
"SearchDatetimeStr": "2020-08-01 09:33:00.838081", # Date of data extraction, [str]
|
|
|
|
|
"SearchItems": {
|
|
|
|
|
"https://www.cian.ru/sale/flat/219924574/:": { # Item URL with https
|
|
|
|
|
"TitleStr": "3-комн. кв., 31,4 м², 5/8 этаж", # Offer title [str]
|
|
|
|
|
"PriceFloat": 10000000.0, # Price [float]
|
|
|
|
|
"PriceSqmFloat": 133333.0, # CALCULATED Price per square meters [float]
|
|
|
|
|
"SqMFloat": 31.4, # Square meters in flat [float]
|
|
|
|
|
"FloorCurrentInt": 5, # Current floor [int]
|
|
|
|
|
"FloorTotalInt": 8, # Current floor [int]
|
|
|
|
|
"RoomCountInt": 3 # Room couint [int]
|
|
|
|
|
}
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
}
|
|
|
|
|
"""
|
|
|
|
|
|
|
|
|
|
##########################
|
|
|
|
|
# Init the Chrome web driver
|
|
|
|
|
###########################
|
|
|
|
|
gChromeExeFullPath = r'..\Resources\GoogleChromePortable\App\Chrome-bin\chrome.exe'
|
|
|
|
|
gExtensionFullPathList = []
|
|
|
|
|
gWebDriverFullPath = r'..\Resources\SeleniumWebDrivers\Chrome\chromedriver_win32 v84.0.4147.30\chromedriver.exe'
|
|
|
|
|
def WebDriverInit(inWebDriverFullPath, inChromeExeFullPath, inExtensionFullPathList):
|
|
|
|
|
# Set full path to exe of the chrome
|
|
|
|
|
lWebDriverChromeOptionsInstance = webdriver.ChromeOptions()
|
|
|
|
|
lWebDriverChromeOptionsInstance.binary_location = inChromeExeFullPath
|
|
|
|
|
# Add extensions
|
|
|
|
|
for lExtensionItemFullPath in inExtensionFullPathList:
|
|
|
|
|
lWebDriverChromeOptionsInstance.add_extension (lExtensionItemFullPath)
|
|
|
|
|
# Run chrome instance
|
|
|
|
|
lWebDriverInstance = None
|
|
|
|
|
if inWebDriverFullPath:
|
|
|
|
|
# Run with specified web driver path
|
|
|
|
|
lWebDriverInstance = webdriver.Chrome(executable_path = inWebDriverFullPath, options=lWebDriverChromeOptionsInstance)
|
|
|
|
|
else:
|
|
|
|
|
lWebDriverInstance = webdriver.Chrome(options = lWebDriverChromeOptionsInstance)
|
|
|
|
|
# Return the result
|
|
|
|
|
return lWebDriverInstance
|
|
|
|
|
|
|
|
|
|
from selenium.webdriver.common.by import By
|
|
|
|
|
from selenium.webdriver.support.ui import WebDriverWait
|
|
|
|
|
from selenium.webdriver.support import expected_conditions as EC
|
|
|
|
|
|
|
|
|
|
# def to extract list of offers from one job
|
|
|
|
|
def OffersByJobExtractDict(inLogger, inWebDriver, inJob):
|
|
|
|
|
# BUG 0 - if timeout - retry the job +
|
|
|
|
|
# BUG 1 - do mouse scroll to to emulate user activity - cian can hold the robot
|
|
|
|
|
# BUG 2 - check the page to retry job offer if page is not next +
|
|
|
|
|
# BUG 3 - RE fall on Апартаменты-студия, 85,6 м², 4/8 этаж +
|
|
|
|
|
lRetryJobBool = True # Init flag if some error is raised - retry
|
|
|
|
|
while lRetryJobBool:
|
|
|
|
|
lRetryJobBool = False # Set false until some another action will appear
|
|
|
|
|
lResult = copy.deepcopy(inJob) # do copy the structure
|
|
|
|
|
lFilterURLStr = lResult["SearchURLStr"]
|
|
|
|
|
inWebDriver.get(lFilterURLStr) # Open the URL
|
|
|
|
|
lDatetimeNowStr = str(datetime.datetime.now())
|
|
|
|
|
lResult.update({
|
|
|
|
|
"SearchDatetimeStr": lDatetimeNowStr, # Date of data extraction, [str]
|
|
|
|
|
"SearchItems": {} # prepare the result
|
|
|
|
|
})
|
|
|
|
|
# Get List of the page
|
|
|
|
|
lNextPageItemCSS = 'div[data-name="Pagination"] li[class*="active"] + li a'
|
|
|
|
|
lNextPageItem = inWebDriver.find_element_by_css_selector(lNextPageItemCSS)
|
|
|
|
|
lPageCounterInt = 1 # Init the page counter
|
|
|
|
|
while lNextPageItem:
|
|
|
|
|
lPageNumberInt = int(inWebDriver.find_element_by_css_selector(css_selector='li[class*="--active--"] span').text) # Get the current page int from web and check with iterator (if not equal - retry all job)
|
|
|
|
|
if lPageNumberInt == lPageCounterInt:
|
|
|
|
|
lOfferListCSSStr = 'div[data-name="Offers"] > div:not([data-name="BannerServicePlaceInternal"]):not([data-name="getBannerMarkup"]):not([data-name="AdFoxBannerTracker"])'
|
|
|
|
|
lOfferList = inWebDriver.find_elements_by_css_selector(css_selector=lOfferListCSSStr)
|
|
|
|
|
for lOfferItem in lOfferList: # Processing the item, extract info
|
|
|
|
|
lOfferItemInfo = { # Item URL with https
|
|
|
|
|
"TitleStr": "3-комн. кв., 31,4 м², 5/8 этаж", # Offer title [str]
|
|
|
|
|
"PriceFloat": 10000000.0, # Price [float]
|
|
|
|
|
"PriceSqmFloat": 133333.0, # CALCULATED Price per square meters [float]
|
|
|
|
|
"SqMFloat": 31.4, # Square meters in flat [float]
|
|
|
|
|
"FloorCurrentInt": 5, # Current floor [int]
|
|
|
|
|
"FloorTotalInt": 8, # Current floor [int]
|
|
|
|
|
"RoomCountInt": 3 # Room couint [int]
|
|
|
|
|
}
|
|
|
|
|
lTitleStr = lOfferItem.find_element_by_css_selector(css_selector='div[data-name="TopTitle"],div[data-name="Title"]').text # Extract title text
|
|
|
|
|
if inLogger: inLogger.info(f"Старт обработки предложения: {lTitleStr}")
|
|
|
|
|
lPriceStr = lOfferItem.find_element_by_css_selector(css_selector='div[data-name="Price"] > div[class*="header"],div[data-name="TopPrice"] > div[class*="header"]').text # Extract total price
|
|
|
|
|
lURLStr = lOfferItem.find_element_by_css_selector(css_selector='a[class*="--header--"]').get_attribute("href") # Extract offer URL
|
|
|
|
|
lOfferItemInfo["TitleStr"] = lTitleStr # set the title
|
|
|
|
|
lPriceStr = lPriceStr.replace(" ","").replace("₽","") # Remove some extra symbols
|
|
|
|
|
lOfferItemInfo["PriceFloat"] = round(float(lPriceStr),2) # Convert price to the float type
|
|
|
|
|
#Check if Апартаменты
|
|
|
|
|
if "АПАРТАМЕНТЫ" in lTitleStr.upper():
|
|
|
|
|
lREResult = re.search(r".*, (\d*,?\d*) м², (\d*)/(\d*) эта.", lTitleStr) # run the re
|
|
|
|
|
lOfferItemInfo["RoomCountInt"] = 1 # Room count
|
|
|
|
|
lSqmStr = lREResult.group(1)
|
|
|
|
|
lSqmStr= lSqmStr.replace(",",".")
|
|
|
|
|
lOfferItemInfo["SqMFloat"] = round(float(lSqmStr),2) # sqm count
|
|
|
|
|
lOfferItemInfo["FloorCurrentInt"] = int(lREResult.group(2)) # Floor current
|
|
|
|
|
lOfferItemInfo["FloorTotalInt"] = int(lREResult.group(3)) # Floor total
|
|
|
|
|
lOfferItemInfo["PriceSqmFloat"] = round(lOfferItemInfo["PriceFloat"] / lOfferItemInfo["SqMFloat"],2) # Sqm per M
|
|
|
|
|
else:
|
|
|
|
|
lREResult = re.search(r".*(\d)-комн. .*, (\d*,?\d*) м², (\d*)/(\d*) эта.", lTitleStr) # run the re
|
|
|
|
|
lOfferItemInfo["RoomCountInt"] = int(lREResult.group(1)) # Room count
|
|
|
|
|
lSqmStr = lREResult.group(2)
|
|
|
|
|
lSqmStr= lSqmStr.replace(",",".")
|
|
|
|
|
lOfferItemInfo["SqMFloat"] = round(float(lSqmStr),2) # sqm count
|
|
|
|
|
lOfferItemInfo["FloorCurrentInt"] = int(lREResult.group(3)) # Floor current
|
|
|
|
|
lOfferItemInfo["FloorTotalInt"] = int(lREResult.group(4)) # Floor total
|
|
|
|
|
lOfferItemInfo["PriceSqmFloat"] = round(lOfferItemInfo["PriceFloat"] / lOfferItemInfo["SqMFloat"],2) # Sqm per M
|
|
|
|
|
lResult['SearchItems'][lURLStr] = lOfferItemInfo # Set item in result dict
|
|
|
|
|
# Click next page item
|
|
|
|
|
lNextPageItem = None
|
|
|
|
|
lNextPageList = inWebDriver.find_elements_by_css_selector(lNextPageItemCSS)
|
|
|
|
|
if len(lNextPageList)>0:
|
|
|
|
|
lNextPageItem = lNextPageList[0]
|
|
|
|
|
try:
|
|
|
|
|
#lNextPageItem = WebDriverWait(lWebDriver, 10).until(EC.visibility_of_element_located((By.CSS_SELECTOR, 'div[data-name="Pagination"]')))
|
|
|
|
|
#lNextPageItem.click()
|
|
|
|
|
inWebDriver.execute_script("""document.querySelector('div[data-name="Pagination"] li[class*="active"] + li a').click()""")
|
|
|
|
|
except Exception as e:
|
|
|
|
|
print(e)
|
|
|
|
|
time.sleep(0.5) # some init operations
|
|
|
|
|
# wait while preloader is active. If timeout - retry all job
|
|
|
|
|
lTimeFromFLoat = time.time() # get current time in float (seconds)
|
|
|
|
|
lDoWaitBool = True
|
|
|
|
|
while lDoWaitBool:
|
|
|
|
|
lPreloaderCSS = inWebDriver.find_elements_by_css_selector(css_selector='div[class*="--preloadOverlay--"]')
|
|
|
|
|
if len(lPreloaderCSS)>0: time.sleep(0.5) # preloader is here - wait
|
|
|
|
|
else: lDoWaitBool = False # Stop wait if preloader is dissappear
|
|
|
|
|
if (time.time() - lTimeFromFLoat) > 15: # check if timeout is more than 15 seconds
|
|
|
|
|
lRetryJobBool = True # Loading error on page - do break, then retry the job
|
|
|
|
|
if inLogger: inLogger.warning(f"Ожидание загрузки страницы более {15} с., Робот повторит задание сначала")
|
|
|
|
|
break # break the loop
|
|
|
|
|
if lRetryJobBool == True: # break the loop if RetryJobBool is true
|
|
|
|
|
break
|
|
|
|
|
lPageCounterInt = lPageCounterInt + 1 # Increment the page counter
|
|
|
|
|
else:
|
|
|
|
|
lRetryJobBool = True
|
|
|
|
|
if inLogger: inLogger.warning(
|
|
|
|
|
f"Следующая страница по списку не была загружена. Была загружена страница: {lPageNumberInt}, Ожидалась страница: {lPageCounterInt}")
|
|
|
|
|
if lRetryJobBool == False: # break the loop if RetryJobBool is true
|
|
|
|
|
# Check dir - create if not exists
|
|
|
|
|
if not os.path.exists(os.path.join('Datasets',lResult['SearchKeyStr'])):
|
|
|
|
|
os.makedirs(os.path.join('Datasets',lResult['SearchKeyStr']))
|
|
|
|
|
# Save result in file
|
|
|
|
|
lFile = open(f"{os.path.join('Datasets',lResult['SearchKeyStr'],lDatetimeNowStr.replace(' ','_').replace('-','_').replace(':','_').replace('.','_'))}.json","w",encoding="utf-8")
|
|
|
|
|
lFile.write(json.dumps(lResult))
|
|
|
|
|
lFile.close()
|
|
|
|
|
|
|
|
|
|
# Инициализировать Google Chrome with selenium web driver
|
|
|
|
|
lWebDriver = WebDriverInit(inWebDriverFullPath = gWebDriverFullPath, inChromeExeFullPath = gChromeExeFullPath, inExtensionFullPathList = gExtensionFullPathList)
|
|
|
|
|
lFilterURLStr = "https://www.cian.ru/cat.php?deal_type=sale&engine_version=2&in_polygon%5B1%5D=37.6166_55.7678%2C37.6147_55.7688%2C37.6114_55.7694%2C37.6085_55.7698%2C37.6057_55.77%2C37.6018_55.77%2C37.5987_55.77%2C37.5961_55.7688%2C37.5942_55.7677%2C37.5928_55.7663%2C37.5915_55.7647%2C37.5908_55.7631%2C37.5907_55.7616%2C37.5909_55.7595%2C37.5922_55.7577%2C37.5944_55.7563%2C37.5968_55.7555%2C37.6003_55.7547%2C37.603_55.7543%2C37.6055_55.7542%2C37.6087_55.7541%2C37.6113_55.7548%2C37.6135_55.756%2C37.6151_55.7574%2C37.6163_55.7589%2C37.6179_55.7606%2C37.6187_55.7621%2C37.619_55.7637%2C37.6194_55.7651%2C37.6193_55.7667%2C37.6178_55.7679%2C37.6153_55.7683%2C37.6166_55.7678&offer_type=flat&polygon_name%5B1%5D=%D0%9E%D0%B1%D0%BB%D0%B0%D1%81%D1%82%D1%8C+%D0%BF%D0%BE%D0%B8%D1%81%D0%BA%D0%B0&room1=1&room2=1"
|
|
|
|
|
lJobItem = {
|
|
|
|
|
"SearchKeyStr": "МСК_Тверской",
|
|
|
|
|
"SearchTitleStr": "Москва, район Тверской", # Title of the search [str]
|
|
|
|
|
"SearchURLStr": lFilterURLStr,
|
|
|
|
|
# URL of the CIAN search [str]
|
|
|
|
|
}
|
|
|
|
|
OffersByJobExtractDict(inLogger = logging, inWebDriver = lWebDriver, inJob = lJobItem)
|
|
|
|
|
```
|
|
|
|
|
<cut/>
|
|
|
|
|
|
|
|
|
|
# Подведем итоги
|
|
|
|
|
Уважаемые роботизаторы.
|
|
|
|
|
|
|
|
|
|
Мы успешно преодолели вторую серию туториалов по созданию роботов в WEB приложениях с помощью open source pyOpenRPA. Готовый проект робота Вы можете найти в репозитории pyOpenRPA [по ссылочке](https://gitlab.com/UnicodeLabs/OpenRPA/-/tree/master/Wiki/RUS_Tutorial/WebGUI_Habr).
|
|
|
|
|
В нашем аресенале уже имеются изученные технологии упраления Desktop и WEB приложениями. В следующей статье-туториале мы остановимся на особенностях роботизированного управления мышью и клавиатурой.
|
|
|
|
|
|
|
|
|
|
Пишите комменты, внедряйте бесплатных роботов, будьте счастливы :)
|
|
|
|
|
|
|
|
|
|
**До скорых публикаций!**
|
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}